




In this episode, Rahul and Stephen continue the theme of Behind the Scenes by showing some of the automation which makes AWS Made Easy possible. In particular, we are going to be talking about:
- Generating the show notes from the descriptions
- Getting the transcript, and running AWS Comprehend on it.
- AWS QuickSight dashboard on the words, perhaps on the analytics. What else can we do with it?
- Running Kendra on the transcript
- Future plans!
Show Notes Generator
As part of each episode, we generate show notes. These show notes become the contents of our awsmadeeasy.com website. For example, check out episode 16 here. In order to create these show notes, we aggregate the text of the custom fields from all of the different segments. When are are doing article reviews, this includes the star rating and “Simplifies / Neutral / Complexity” flags that we use.
Comprehend to Tag the Transcripts
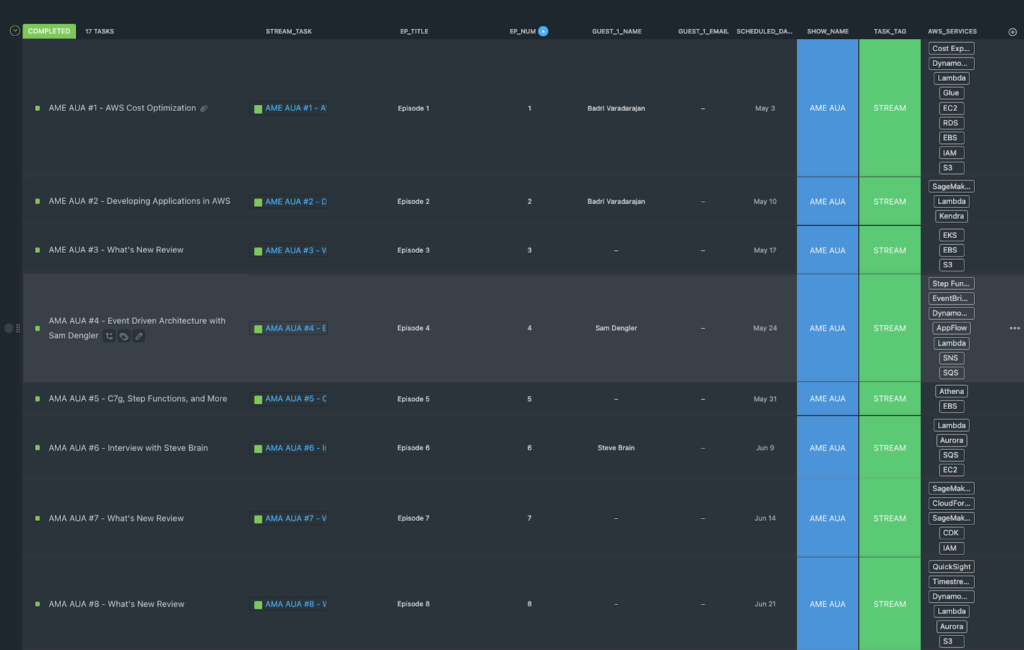
We use AWS Comprehend to Tag the transcripts. The main idea is that Comprehend can process natural language and attach semantic structure, such as the labeling of quantities and entity names and types. To demonstrate this, we use comprehend to scan for named AWS Services. This allows us to filter for episodes where we have mentioned certain services.
This is what it looks like from within ClickUp.
Rahul did a demo of getting started with AWS Comprehend in Episode 14.
Check out our repository for some sample AWS Comprehend code: https://github.com/AWSMadeEasy/LetsCode/tree/ep14
QuickSight Dashboard
We use QuickSight to understand metrics regarding our LiveStream. In this case we used the word-cloud feature, but QuickSight would also be very good for aggregating things like view count of the various Tweets, YouTube views, and LinkedIn posts associated with this.