AWS offers two services for data preparation and data wrangling: AWS Glue Data Brew and Amazon SageMaker Data Wrangler.
They are both designed for data wrangling, preparing, cleaning, transforming, and exporting for downstream apps like analytics and training machine learning models. Their key functionality is identical.
Nevertheless, they differ in these aspects:
- AWS Glue Data Brew has a much more user-friendly user interface than AWS SageMaker Data Wrangler
- AWS Glue Data Brew is much simpler, and can run all transformations without a single line of code
- AWS SageMaker Data Wrangler allows code export of the transformations and is ideal for advanced features engineering in AWS SageMaker
If you do not require running any custom code for transformations, use AWS Glue Data Brew.
Let’s discuss each solution in detail.
AWS Glue DataBrew
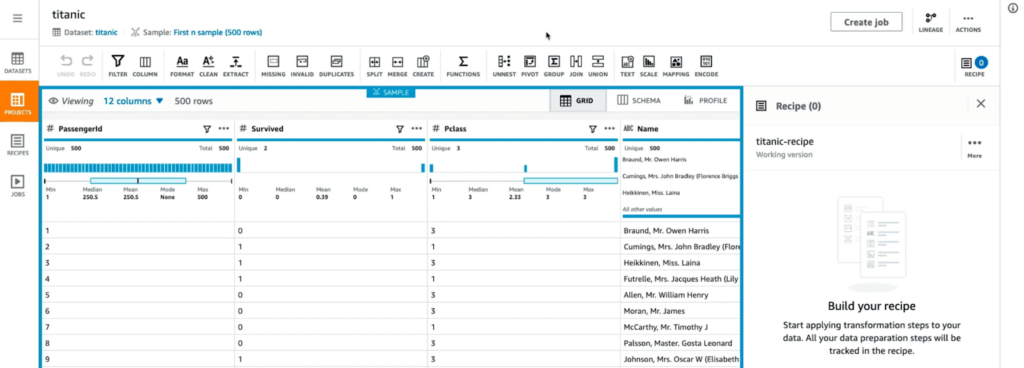
- It is a data cleaning ETL service – a part of AWS Glue service family, an AWS fully managed ETL service
- It allows you to:
- Create a project
- Connect to data sources – S3, RedShift, RDS etc.)
- Create data sets
- Set up transformations in very rich UI data for data cleaning and handling missing data
- Run transformations
- Export the results to csv or other data file formats
- Once you import a data set, you can run a profile job producing basic summary statistics on the dataset, correlation matrix between the columns etc. – AWS SageMaker Data Wrangler does not have this functionality
AWS SageMaker Data Wrangler
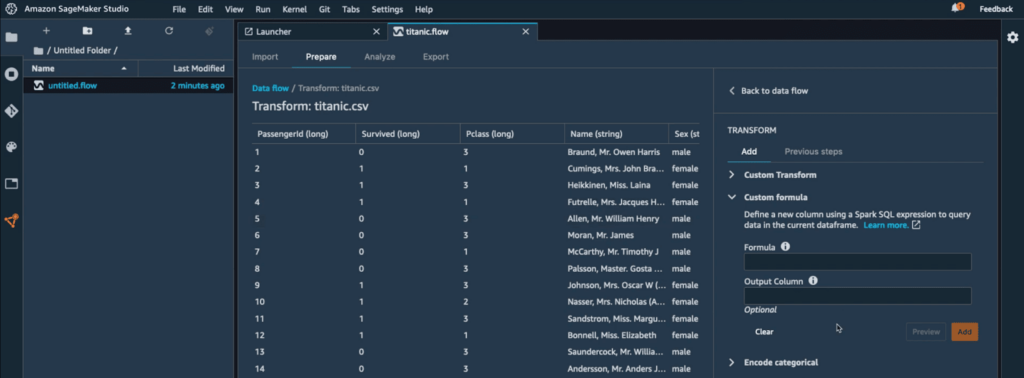
- It is a Jupyter-based UI, data transformation service for machine learning
- You can connect to S3, or Athena and import to a graphical user interface data for data cleaning and handling missing data
- Unlike AWS Glue Data Brew, AWS SageMaker Data Wrangler offers running custom Python scripts (Python Pandas / Python PySpark) or PySpark SQL
- Unlike AWS Glue Data Brew, it allows you to build a quick analysis with a few mouse clicks – a quick, immediately trained model
- It can export to Python code or Jupyter Features Code or SageMaker Data Wrangler Job
Summary
For pure ETL data cleaning and simple transformations, use AWS Glue Data Brew. For data wrangling, custom-code transformations, and inputs to AWS SageMaker use AWS SageMaker Data Wrangler.