




New Instance Types – C7g, M6a, C6a, oh my!
We spent the majority of the show discussing the new C7g instance, which was released to General Availability last week. This is based on the new Graviton 3 processor, which we discuss at length.
We (AWS Made Easy) did a study on the Graviton3 performance, compared with the Graviton2 and a comparable C6i instance, which runs Intel Xeon Scalable CPUs. The lessons learned from the study are that, compared to the Graviton2, the Graviton3 offers a 20-35% performance increase for only a 6% cost increase. See the study for more details and benchmarks.
The study is available here: https://awsmadeeasy.com/blog/aws-graviton3-adoption-in-esw-capital/
In the discussion, we referenced a talk about the adoption of the Graviton processor. This is the AWS re:Invent 2021 Keynote with Peter DeSantis, 39:31. The keynote, or at least this segment, is well worth a watch.
We spent a bit of time talking about how ARM-based processors, such as the Graviton3 and Apple’s famed M1-series of CPUs, have far lower Thermal Design Power (TDP). In addition to taking far less power, ARM-based CPUs are where the innovation is occurring. For more details, see Apple Announces The Apple Silicon M1: Ditching x86 – What to Expect, Based on A14, from AnandTech. There is a famous visual in that article, shown below.
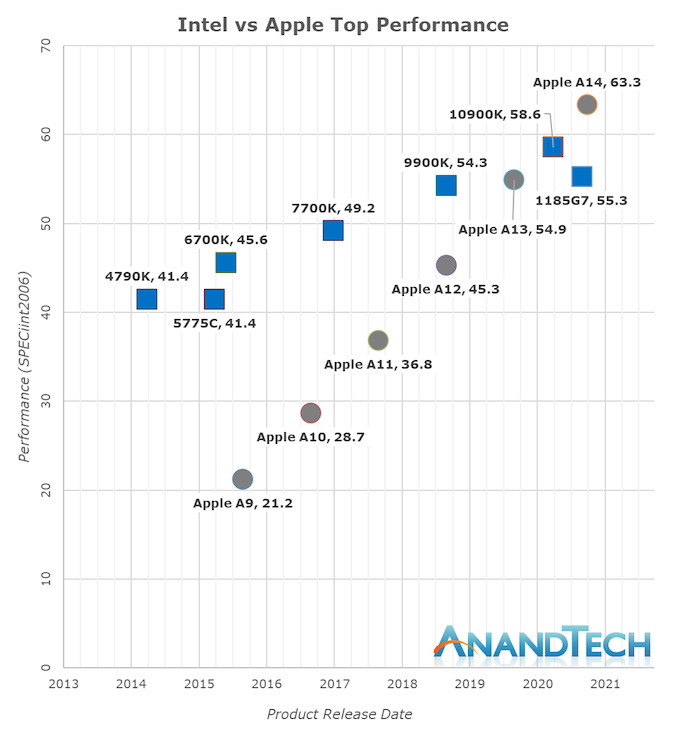
We see Apple’s ARM-based CPUs growing in performance, whereas Intel’s CPUs are stagnating. The Graviton3 follows a similar trajectory.
We then shift gears into talking about the AMD EPYC-Milan processor, which is powering the M6a and C6a processors. We couldn’t do a better job at breaking down the specs than the famous Linus Sebastian, so we played a clip instead. They key takeaway is shown in the following screengrab:
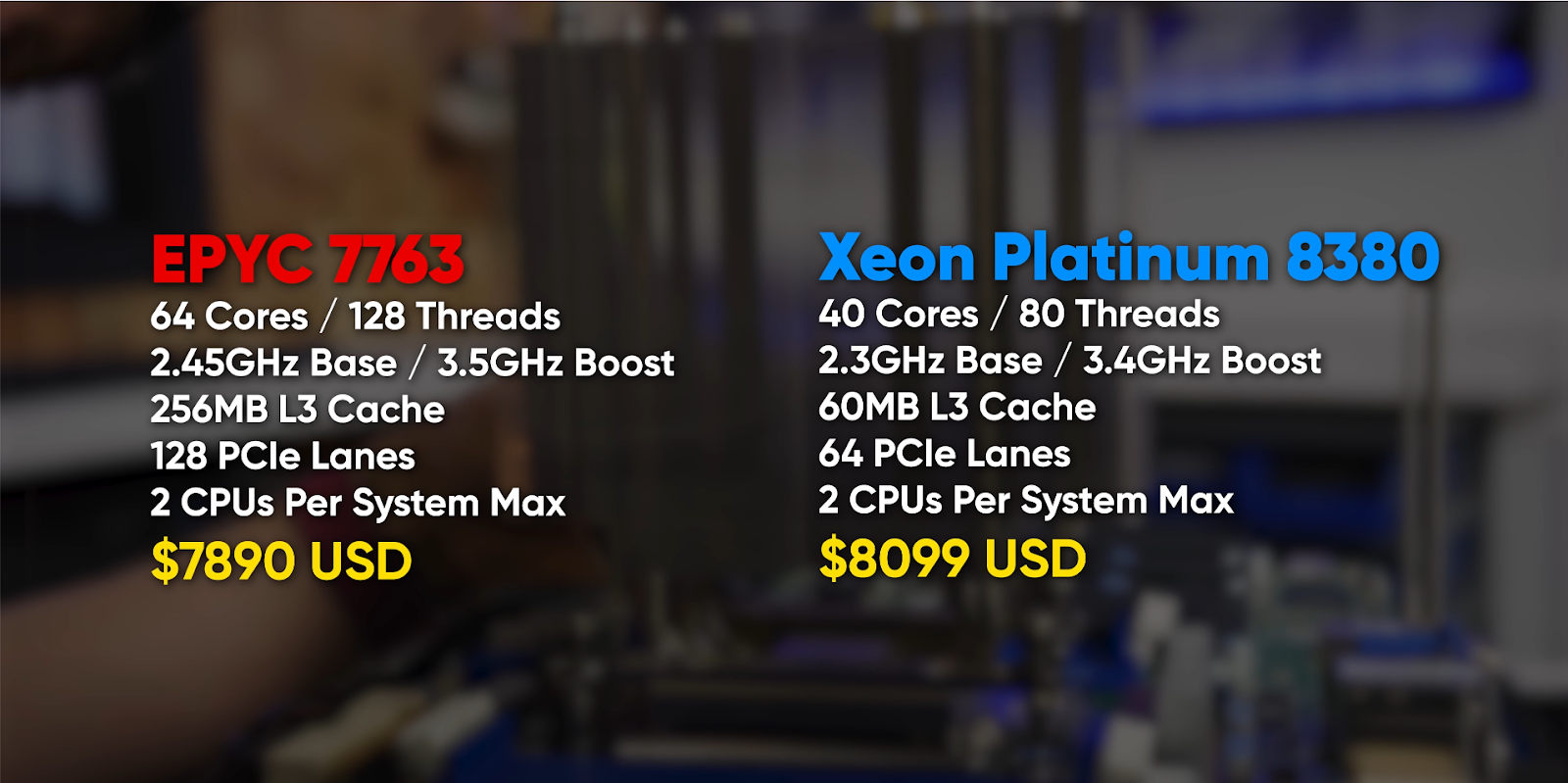
But remember, when considering operating this in a data center, have a look at that giant heatsink. This is because these CPUs, like their Intel counterparts, are power hungry.

The concluding advice from Rahul: Use the Graviton3 unless you have a compelling reason not to. Their price/performance is superior to Intel and EPYC in most general server workloads.
Announcing new workflow observability features for AWS Step Functions
We then discuss the “New workflow observability features for AWS Step Functions” announcement. There is a detailed accompanying blogpost. Note that step functions are essentially ways of orchestrating collections of lambda functions, which can become very similar to a collection of microservices. These are notoriously difficult debug and reason about.
I showed a fun video with an example of this (language warning).
New for AWS DataSync – Move Data Between AWS and Other Public Locations
Next, we discussed the announcement entitled New for AWS DataSync – Move Data Between AWS and Other Public Locations. This announcement makes it easier to synchronize data sources, such as Google Cloud Storage or Microsoft Azure FIles, with AWS data sources such as S3 or EFS.
Our conclusion: On the one hand, this could be a useful tool, on the other hand it:
- Encourages a multi-cloud approach, which is difficult and usually unnecessary.
- Can get extremely costly, as every cloud vendor charges high egress fees.
Once Frenemies, AWS and ElasticSearch are now Besties
For our final segment, we briefly review an article by VentureBeat entitled “Once Frenemies, AWS and ElasticSearch are now Besties.” This article describes the relationship between Elastic Co. and AWS. Last year, AWS forked ElasticSearch into OpenSearch, due to a change in license initiated by Elastic. It seemed at the time to be a sour relationship, and there was plenty of gossip about it.
However, things seemed to have turned, and the Elastic / AWS Partnership seems strong. How did things evolve this way? Is this a good outcome for all?
Our conclusion: The power of the AWS Marketplace is strong, and it was smart of Elastic to make things work. Marketplace allows you to use enterprise software such as ElasticSearch without a long and convoluted procurement process, and instead paying by usage. Elastic has a strong product offering on top of ElasticSearch, namely the Elastic Logstash Kibana (ELK) stack. The visualizations produced by Kibana are, at present, superior to those produced by Amazon.